
Fuzzing the Vyper Compiler

Introduction
Vyper is a pythonic smart contract language for EVM blockchains. Known for its simplicity and security-focused approach, Vyper emphasizes readability, transparency, and ease of audit, intentionally limiting complex features to reduce potential attack surfaces and make the codebase more manageable.
Solidity’s popularity and support have led to a large ecosystem of tools and resources contributing to its security and reliability. Unfortunately, Vyper lacks similarly extensive support in its development and testing. To ensure Vyper's security continues to improve, it is crucial to enhance its ecosystem with dedicated tools and resources for testing and verifying the integrity of the compiler.
Our team strongly appreciates the Vyper language and is deeply committed to enhancing the security of projects built with it. Having spent extensive time auditing Vyper-based projects, we recognize the strengths and unique security challenges of using Vyper for smart contract development.
Introducing Vyzzer, a fuzzing tool designed specifically for the Vyper compiler. Driven by our passion for the language and our commitment to strengthening its ecosystem, we created Vyzzer to identify potential vulnerabilities in the compiler and runtime environment proactively. This tool provides developers and auditors with a powerful resource to ensure safer, more reliable Vyper smart contracts. Through this contribution, we hope to support the broader adoption of Vyper and empower the community with better security practices and tooling.
Fuzzing
Fuzzers are powerful tools for improving software security, designed to identify vulnerabilities, bugs, and edge cases by subjecting software to a wide range of unexpected or invalid inputs. Unlike traditional testing methods that rely on predefined test cases, fuzzers excel at generating novel inputs that can explore untested paths in the codebase, uncovering hidden flaws that might otherwise go unnoticed.
Developing a fuzzer for any language presents unique challenges.
Valid Syntax and Semantics
One of the primary challenges for backend fuzzing lies in generating complex and valid input. Compilers expect structured code that follows precise syntactical and semantic rules, so the fuzzer must produce code snippets that are syntactically valid without grammar errors and semantically meaningful to avoid trivial parsing errors, but still random and even odd enough to test unexpected corner cases and branches of the compiler’s code. Structure-aware fuzzing helps address this challenge by generating inputs that adhere to the compiler's expected format while allowing enough variation to explore unanticipated behaviors.
Tracking Execution Paths
Attaining high coverage demands intelligent mutation strategies or specialized feedback mechanisms to navigate complex code paths within the compiler. The fuzzer needs to track which parts of the compiler’s code are executed during testing, an essential feature for evaluating its effectiveness in covering diverse execution paths.
Detecting Non-Crashing Bugs
Not all bugs lead to crashes. Some compiler bugs manifest as incorrect code generation, optimization failures, or semantic misinterpretations. Determining the expected behavior of complex code inputs is challenging. For languages with multiple compilers, differential testing can be used to compare output, in this case, we’ll have to compare different versions of the Vyper.
Keeping Up with Compiler Changes
Compilers evolve, with new features, optimizations, and bug fixes continuously being added. The fuzzer needs to adapt to these changes and be updated frequently to remain effective.
Implementation bias
Biases can arise from how inputs are generated, mutated, or converted, potentially leading the fuzzer to overemphasize certain paths while neglecting others. As a result, edge cases or vulnerabilities may remain untested, reducing the overall effectiveness.
Performance
The efficiency of the fuzzer determines the volume and quality of test cases it can generate and execute within a given timeframe. Slow or resource-intensive fuzzers can significantly hinder the discovery of vulnerabilities, especially when targeting large-scale or complex systems.
Below, we present the developed fuzzing tool and how it addresses these challenges, providing a robust framework for thoroughly testing the Vyper compiler and enhancing its security and reliability.
The Vyzzer
The fuzzing framework is developed in a modular fashion allowing flexibility, extensibility, and ease of updates.
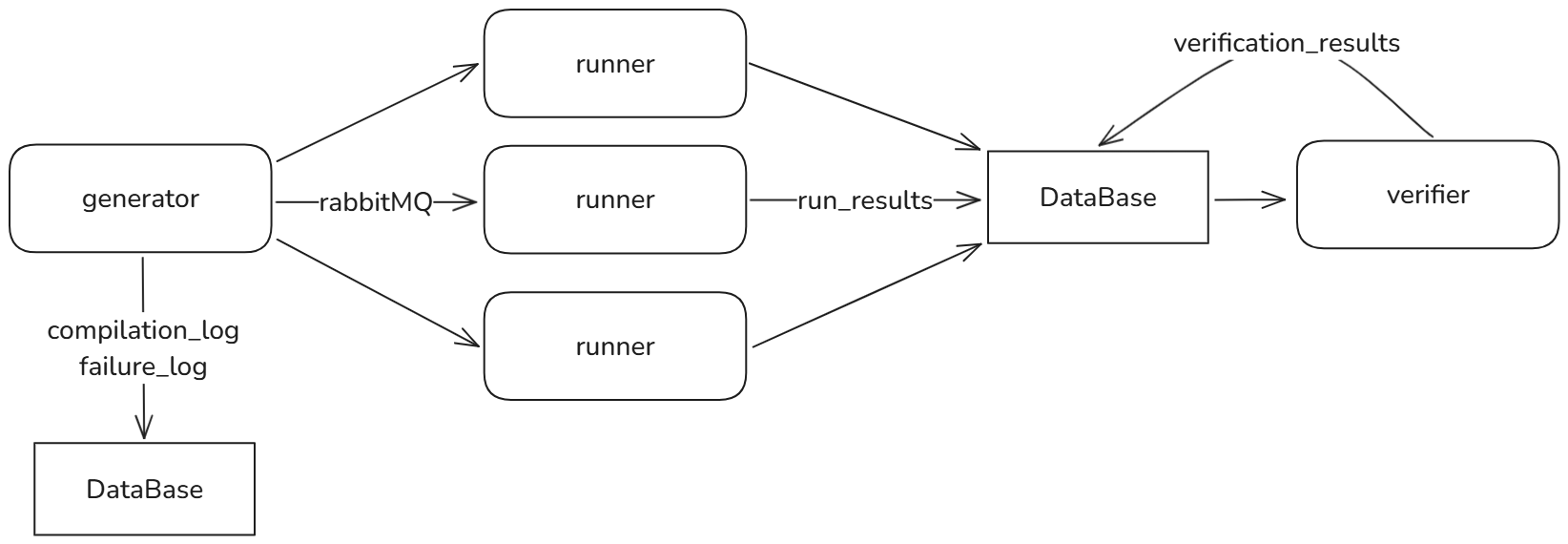
Code Generator
This module serves as the core of the fuzzing tool and is responsible for generating and managing test inputs for the Vyper compiler. At its foundation lies Atheris, a coverage-guided Python fuzzing engine built on libFuzzer. To enhance its effectiveness, we leverage the libprotobuf-mutator integrated within Atheris, enabling us to target the Vyper compiler's back-end directly while minimizing parsing errors and related issues by allowing us to define a structure of payload. The fuzzing engine utilizes Python coverage data to guide its mutations of protocol buffer inputs - protobuf messages, ensuring structure-aware fuzzing. This message is eventually turned into a contract source code.
message Contract {
repeated VarDecl decls = 1;
repeated Func functions = 2;
ContractInit init = 3;
optional DefaultFunc def_func = 4;
}
Integrating libprotobuf-mutator necessitates translating protocol buffer payloads into valid Vyper source code that can be fed to the compiler. This translation is handled by the converter module, which serves as a critical bridge between the structured proto inputs and the expected syntax of the Vyper language. The converter processes each field of the protocol buffer payload, mapping data types and operations, and constructs to their Vyper equivalents while adhering to the language's strict syntax and semantics.
class TypedConverter:
...
def visit(self):
"""
Runs the conversion of the message and stores the result in the result variable
"""
for i, var in enumerate(self.contract.decls):
if i >= MAX_STORAGE_VARIABLES:
break
self.result += self.__var_decl_global(var)
self.result += "\n"
if self.result != "":
self.result += "\n"
if self.contract.init.flag or len(self._immutable_exp):
self.result += self.visit_init(self.contract.init)
self.result += "\n"
self._func_tracker.register_functions(self.contract.functions)
While correct syntax is ensured by the protocol buffer template, guaranteeing proper semantics demands additional attention to the converter’s logic. The translation algorithm must respect all the rules and constraints of Vyper, such as type compatibility, variable scope, function behavior, avoiding cyclic function calls, and more, to ensure the generated source code is both meaningful and valid for deeper compiler testing.
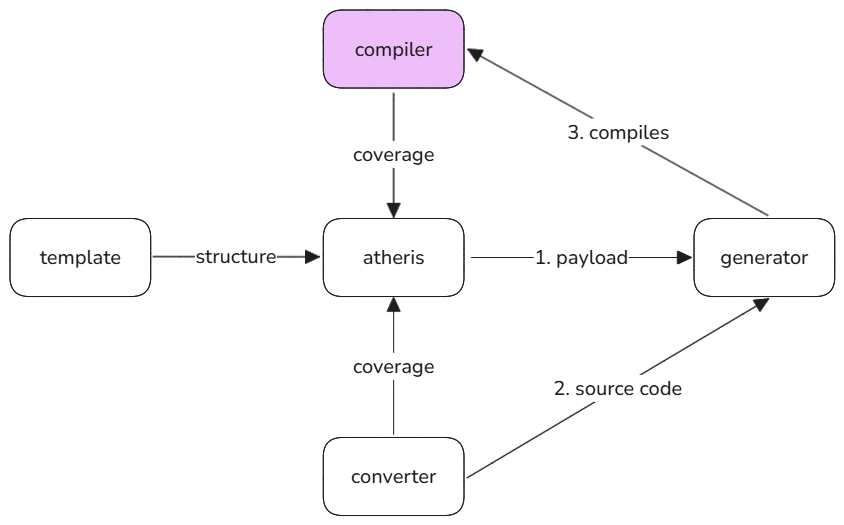
Putting it all together, the Generator service obtains the protobuf message, converts it to a Vyper contract, compiles the contract (to guide Atheris so the next message is generated according to the coverage of the current one), saves the contract to DB, and puts it in a queue so that the next service, Runner, can deploy and run it.
The Generator module is designed to be highly adaptable, allowing the replacement of the converter or the addition of multiple converters for different Vyper versions. This flexibility enables the generation of equivalent code across various versions, facilitating differential fuzzing.
This design allows the replacement of the fuzzer engine, providing flexibility to adapt the framework to different fuzzing backends or methodologies without requiring significant changes to the overall architecture. Modularity ensures that the generator remains compatible with a wide range of fuzzing strategies, from purely random input generation to advanced coverage-guided approaches, enabling the framework to evolve as new fuzzing technologies and techniques emerge.
The Runner
Runners are responsible for compiling, deploying, and executing the generated source code on the EVM. This process involves compiling the Vyper code to bytecode, deploying it to a virtual EVM and executing various functions with generated inputs. The runners capture critical data, such as storage, execution outcomes, runtime errors, and gas consumption, all provided by Titanoboa. By focusing on the complete lifecycle from source code to EVM execution, runners play a pivotal role in validating the robustness of the Vyper compiler and its outputs.
Runners enable differential testing across compiler versions or configurations by working asynchronously and independently from one another. For example, the default Titanoboa interpreter can be replaced with any other Vyper-compatible interpreter, enabling the creation of a custom source of truth, which is also valuable for conducting cross-version fuzzing of the interpreters. By supporting such modularity, the Runner module not only facilitates comprehensive testing but also ensures its compatibility with evolving Vyper tools and environments.
The Verifier
The Verifier module validates the results generated by the runners, ensuring the Vyper compiler behaves as expected across configurations and versions. Its primary goal is to detect inconsistencies and anomalies. By analyzing data captured during test execution, the Verifier serves as the final step in the fuzzing process. It supports custom verification logic for all retrieved data types, allowing tailored validations to meet specific testing needs.
How to use
Since there is no single specification or guaranteed source of truth for the Vyper compiler, the fuzzer must be used with a specific version to compare results and track discrepancies. It is primarily designed for general fuzz testing of new versions of Vyper against older versions, as well as for testing various configuration parameters of the compiler. This enables the identification of regressions, bugs, or unexpected behavior that may arise when updating or changing Vyper.
To test the Vyper compiler, we have implemented three differential fuzzing setups. These configurations are designed to compare the behavior of different versions or configurations of Vyper, enabling us to identify inconsistencies, regressions, or unexpected behaviors.
Vyper 0.4.0 vs. Vyper 0.3.10
This setup compares the outputs and behaviors of the latest stable version (0.4.0) against its predecessor (0.3.10). By fuzzing both versions with equivalent inputs, we can detect regressions, differences in gas efficiency, and variations in runtime behavior, ensuring that updates have not introduced unintended changes. The challenge for this setup lies in generating two equivalent source codes from a single proto template. To achieve this, the proto template must include only features that are compatible across both versions being tested. Additionally, the converters must account for any changes in runtime behavior introduced by the new version, ensuring that the generated code accurately reflects the semantics of both versions. Another caveat is the validation of results; extensive updates in the new version may lead to significant differences in error reporting or runtime behavior, complicating the verification process. These discrepancies require the validation logic to be adaptable and capable of interpreting varied outputs while ensuring meaningful comparisons between versions.
Vyper 0.3.10 Optimization Flags
Tests Vyper 0.3.10 with different optimization flags enabled. By comparing outputs with and without optimizations, this setup validates the correctness of optimization techniques, ensuring they do not compromise functionality or introduce discrepancies in the compiled bytecode.
Vyper 0.4.0 IR vs. 0.4.0 Experimental Codegen (Venom)
In this setup, the IR of Vyper 0.4.0 is compared against its experimental code generation (Venom). It allows for testing the stability and correctness of the new code generation approach, ensuring compatibility with the existing IR pipeline and identifying potential issues during its early stages of implementation.
Similarly, anyone can create a custom setup to test various tools during their development by comparing their correctness against the existing Vyper implementation. For example, this approach can be used to test the ZK Vyper compilers, new interpreters, or even a completely new Vyper compiler implementation. By leveraging the fuzzer’s ability to generate equivalent test cases and compare outputs, developers can ensure that their tools align with the expected behavior of Vyper, identifying inconsistencies or deviations early in the development process.
In addition to version comparisons, the fuzzer can also be used during the implementation or modification of language features. By configuring the proto templates, targeted fuzzing can be applied to specific areas of the Vyper language, allowing developers to test the behavior of newly introduced features or changes in isolation. This targeted approach helps ensure that the compiler properly handles any new functionality, minimizing the risk of introducing breaking changes or vulnerabilities. Furthermore, developers can implement their own source of truth or specification, serving as a baseline for validating the correctness of new features. This allows for greater flexibility in defining expected behaviors and ensuring that modifications align with the intended design of the language.
Ways to improve
There are several possible areas for improvement to enhance the robustness and efficiency of the fuzzer. Addressing these areas will help ensure broader coverage and more reliable results.
Full Vyper Coverage
Currently, more than half of the Vyper language (0.3.10) is covered in the protobuf template and its converter with our best effort to handle nuanced semantics. Implementing more language features would enable the fuzzer to exercise the full range of Vyper capabilities.
Optimal Implementation of the Converter
Refactor the converter to reduce overhead during translation from proto payloads to Vyper source code. This includes optimizing algorithms for type mapping, function generation, and variable tracking. Possibly, implementing performance-critical components in faster languages to enhance execution speed and overall efficiency.
Optimal Implementation of Fuzzer Modules
Address known issues, such as resource leaks in runners, to improve the stability and reliability of the fuzzer during prolonged fuzzing. Refactor the modules (e.g., Generator, Runner, Verifier) to minimize interdependencies, making them easier to maintain and extend.
Execution with sanitizers for memory or storage
Utilizing sanitizers is an effective method to identify issues related to incorrect memory or storage usage during the compilation/execution of the source code. These sanitizers help detect uninitialized memory access, out-of-bounds operations, and inconsistencies in storage handling.
Results
The fuzzer is equipped with ready-to-go setups as described earlier, allowing users to quickly begin testing Vyper versions, configurations, or implementations. The current implementation, Vyzzer, is a proof of concept and has not yet been thoroughly tested or used extensively. However, even in its preliminary state, it has demonstrated its potential for uncovering issues efficiently. To validate its functionality, we conducted a targeted search for already known bugs. The fuzzer successfully rediscovered known issues within minutes, even on a less-than-optimal machine. This result underscores the tool's effectiveness in identifying vulnerabilities and highlights its potential as a valuable asset for the Vyper ecosystem.Continued testing and refinement will further enhance its capabilities and reliability.


{kind=link}